osd如果用vmware快照还原会有问题
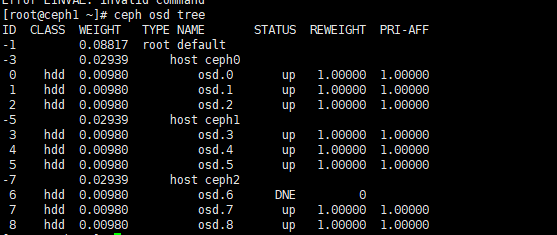
ceph osd tree 查看osd对应关系
第一章ceph的原理与架构
ServerSAN与传统存储
Server SAN: 就是利用普通的服务器的存储资源实现存储资源池的方式
传统存储: 一般都是专有的存储硬件
对比:
性能对比: Server SAN服务器数量达到一定量可以超越传统存储
稳定性对比: 传统存储依赖于硬件的稳定性,ServerSAN是基于软件的稳定性
数据的可靠性: 传统存储一般是通过raid来保证数据的可靠性,Server SAN 通过副本机制来保证
扩展性对比: 传统存储 增加硬盘、升级控制器 Server SAN 支持线性扩展 支持到PB级别的容量
管理性对比: 传统存储需要专人维护 ServerSAN 一般提供web界面并且可以直接管理节点
使用场景: 高IO,业务密集的场景 传统存储依然有用武之地 承载的数据量小 适用于传统存储
海量存储场景中 比如大数据 Server SAN适合所需容量特别大的场景
存储从使用上进行分类:
块存储: 表现形式: 就是主机上的一个磁盘 (硬盘、U盘、光盘….)
DAS 直连式存储: 通过前端总线和存储设备直连
SAN 存储区域网络:服务器和存储直连网络,通过传输介质的不同 SAN的类型不同 ip-san fc-san
ceph: 通过rbd提供块存储 (ceph可以直接给服务器提供一块磁盘)
使用: 不能直接使用 需要分区 格式化 挂载 才可以使用; 对文件全管理 编辑文件/删除文件/保存文件…
文件系统存储: 表现形式: 就是一个共享目录
NAS 网络附加存储 通过网络挂载一个远程的共享目录到本地,就像使用本机上的目录一样来进行存储
CIFS文件共享 windows 上实现
NFS 文件共享 Unix/Linux 上实现
glusterfs 分布式文件系统
moosefs 分布式文件系统
ceph 文件系统存储 cephfs
使用:需要挂载 编辑文件/删除文件/保存文件 ….
对象存储: 从使用上来感受 提供一个在线的接口(一般是http的形式) 直接上传文件/下载文件
从数据上来感受 以对象为单位 ,不再有文件的层次结构 只关注对象
s3的对象存储
swift的对象存储
rgw的对象存储
使用: 上传文件/下载文件/删除文件 不能直接编辑文件
对象存储 天生就有web化的优势; 现在很多 图片、音频、 学习视频
http://s3.example.com/cl260-1.mp4 ——> 很容易被web调用 图床 学习空间
非结构化数据: 音频 视频 文本 各种文件
存储的架构分类:
集中式存储:通过单一存储设备可以直接提供存储资源
DAS NAS SAN
分布式存储: 通过软件来实现分布式架构
moosefs glusterfs ceph
ceph起源
ceph SDS 软件定义存储 是一个开源软件 LGPLV2的协议开源 统一的存储解决方法 可以提供 三类存储
2014年红帽收购以后 ——>红帽的CEPH存储 RHCS
Ceph是提供了软件定义的,统一存储解决方案的开源项目
Ceph是一个分布式、可扩展、高性能、不存在单点故障的存储系统(支持PB级规模数据)
同时支持块存储、文件系统存储、对象存储(兼容swift和S3协议)
ceph哲学
1. ceph中所有的组件都是支持线性扩展的 (每个组件都可以部署多个,不存在单点故障)
2. 所有的解决方案都是开源的,是纯软件来实现的
3. 不依赖于特定的硬件,普通的x86架构就可以满足
4. 每个组件必须尽可能拥有自我管理和自我修复的能力
目标: 轻松扩展到PB级别、提供不同场景下的高性能存储、数据高可靠性
在生产中有大量应用的: rgw 对象存储 rbd 块存储 cephfs 文件系统存储用的非常少
CEPH的云场景应用: 1. ceph可以通过RBD给云上的云主机或者云平台提供各种块设备,满足虚拟化的存储要求
2. ceph还可以通过对象存储,给用户带来海量的存储空间
ceph可以成为云化的资源池
ceph的技术创新
1. rados (可靠的自主分布式对象存储)
2. 使用CRUSH(可扩展哈希下的受控复制)算法自动计算应存储对象的位置
3. 任何客户端都能够使用CRUSH算法来查找对象的存储位置,因此无需与中央查找服务器通信就能找到对象
4. 客户端可以直接与存储对象的Ceph节点通信来获取对象
5. 客户端可以直接与存储对象的Ceph节点通信来获取对象
ceph的技术特点
l CRUSH算法能够根据基础架构变化而动态调整 扩容 迁移 镜像
l 复用数据定位快速响应故障
l 无中央查找服务器
l 不需要位置元数据
l 客户端与Ceph节点直接通信
l 多个客户端并行访问,提高吞吐量 网络要求很高
l 所有存储设备独立并行运行
l 自动数据保护 副本机制 纠删码机制
ceph的文件存储流程(文件系统的存储为例):
ceph的架构及组件
提供存储功能的模块:
RBD: ceph 用来提供块存储
rados gw: 用来提供对象存储网关 实现 s3和swift现成的接口 应用程序直接对接就可以使用
cephfs: 用来提供文件系统存储
ceph的组件:
OSD: ceph集群中唯一的存储组件,用来存储用户数据;负责数据的维护
l Ceph集群中唯一能存储用户数据的组件,同时用户也可以发送读命令来读取数据。
l 在集群中有多少个OSD进程就有多少块磁盘
l 每个OSD对应一块磁盘,磁盘会使用文件系统格式化,支持filestore和bluestore驱动。
l OSD设计目标是尽可能接近计算力与物理数据的距离,让集群的性能能够达到最高效。CRUSH算法用于将对象存储到OSD中。
l 对象被自动复制到多个OSD,客户端在读写数据时始终访问primary OSD,其他OSD为secondary OSD,在集群故障时发挥重要作用。
mon: 维护整个集群的状态和映射信息 整个集群的入口
l Ceph monitor通过保存一份集群状态映射来维护整个集群的健康状态。它分别为每个组件维护映射信息,包括OSD map、MON map、PG map和CRUSH map
l 所有集群节点都向MON节点汇报状态信息,并分享它们状态中的任何变化
l Ceph monitor不存储数据
l MON需要配置为奇数个,只有超过半数正常,Ceph存储集群才能运行并可访问
mgr: 监控集群运行的状态和指标,可以提供web管理界面;还可以对接第三方监控插件(zabbix 普罗米修斯….)
l MGR提供一系列集群统计数据,在较旧版本的Ceph中,这些数据大部分是由MON收集和维护,负载太高
l 如果集群中没有MGR,不会影响客户端I/O操作,但是将不能查询集群统计数据。建议每集群至少部署两个MGR
l MGR将所有收集的数据集中到一处,并通过tcp的8443端口提供一个web界面对集群进行管理
l 通过第三方模块实现的 datadog 数据狗 8443 web界面 普罗米修斯提供监控
mds:元数据服务器 缓存元数据到内存中(如果不需要cephfs的文件系统存储,那么可以不部署mds)
l MDS只为CephFS文件系统跟踪文件的层次结构和存储元数据。MDS不直接提供数据给客户端,从而消除了系统中故障单点。
l MDS使用RADOS存储元数据,MDS本身只在内存中缓存元数据以加速访问 主备部署
l 访问CephFS的客户端首先向MDS发出请求,以便从正确的OSD获取文件
l MDS在配置的时候 会要求配置两个存储池 metadata 元数据池 data数据池
ceph的访问方式
l Ceph原生API(librados)
p Ceph原生接口,可以通过该接口让应用直接与RADOS协作来访问Ceph集群存储的对象
p Ceph RBD、Ceph RGW以及CephFS都构建于其上
p 如果需要最高性能,建议在应用中直接使用librados。如果想简化对Ceph存储的访问,可改用Ceph提供的更高级访问方式,如RGW、RBD、CephFS
l Ceph Object Gateway
p 利用librados构建的对象存储接口
p 通过REST API为应用提供网关
p 支持S3和swift接口
l Ceph Block Device
p 提供块存储
p 由分散在集群中的不同的OSD中的个体对象组成
p Linux内核挂载支持
p QEMU、KVM和Openstack Cinder的启动支持
l Ceph File System
p 并行文件系统,元数据由MDS管理 缓存 进行加速
ceph的访问流程
1. client从mon获取集群的映射信息包括 OSD、MON、MDS等映射…
2. 获取对象ID和存储池的名字
3. 通过hash 算出对象存储的PG
4. 通过crush得出PG所映射的一组OSD
5. 找到主OSD 建立访问
ceph的寻址流程
• File à Object映射:将用户态的file映射成rados能够处理的object,按照统一大小切块并分配id,方便管理以及对多个object并行处理
• Object à PG映射:一个PG负责组织若干个object,但一个object只能被映射到一个PG中。同时,一个PG会被映射到n个OSD上,而每个OSD上都会承载大量的PG。 在file被映射为一个或多个object之后,就需要将每个object独立地映射到一个PG中去。当有大量object和大量PG时,RADOS能够保证object和PG之间的近似均匀映射。
• PG à OSD映射:将作为object的逻辑组织单元的PG映射到数据的实际存储单元OSD。RADOS采用CRUSH算法来实现PG到OSD的映射。
ceph 数据写入流程
正常写入:
• client 创建cluster handler
• client 读取配置文件
• client 连接上monitor,获取集群map信息
• client 读写io 根据crush map算法请求对应的主osd数据节点
• 主osd数据节点同时写入另外两个副本节点数据
• 等待主节点以及另外两个副本节点写完数据状态
• 主节点及副本节点写入状态都成功后,返回给client,io写入完成
异常写入:
• client连接monitor获取集群map信息
• 同时新主osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主
• 临时主osd2会把数据全量同步给新主osd1
• client IO读写直接连接临时主osd2进行读写
• osd2收到读写io,同时写入另外两副本节点
• 等待osd2以及另外两副本写入成功
• osd2三份数据都写入成功返回给client, 此时client io读写完毕
• 如果osd1数据同步完毕,临时主osd2会交出主角色
• osd1成为主节点,osd2变成副本
第二章ceph的安装与扩容
生产环境最小规划
l 至少三个MON节点
l 至少三个OSD节点(每节点可以有多个OSD进程)
l 至少两个MGR节点
l 如果使用CephFS,至少需要两个配置完全相同的MDS节点
l 如果使用Ceph RADOSGW,则至少需要两个RGW节点
容器硬件配置推荐
OSD要求:
规划硬件常见错误
l 仍然使用旧的、性能较差的硬件用于 Ceph。
l 在同一个池中使用不同的硬件。
l 使用 1Gbps 网络而不是 10Gbps 或更快的网络。
l 没有正确设置公共和集群网络。
l 使用 RAID 作为数据保护
l 在选中驱动器时只考虑了价格而没有考虑性能或吞吐量。
l 当用例需要 SSD 日志时,在 OSD 数据驱动器上进行日志。
l 磁盘控制器的吞吐量不足。
ceph的版本
ceph的部署方式
• 纯手动部署
• 部署极其复杂
• 便于初学者理解具体的工作机制
• ceph-deploy
• ceph早期部署方式
• ceph-ansible
• RHCS3的部署方式
• cephadm
• ceph容器化部署方式
• ceph官方和红帽推荐
cephadm部署
cephadm的组成: cephadm ——> python3 脚本 cephadm orchestrator 编排器
cephadm部署的必要条件:
cephadm 脚本 ——> 社区中可以下载 redhat 购买RHCS产品
容器环境 ——> docker/podman
python3的执行环境 ——> cephadm 是拿python写的脚本
时间源 两个节点的时间误差 不能超过0.05s 生产环境中建议自建时间源
时间源的服务器: NTP Server、 chrony
cephadm的好处:
1 . 简化部署的难度,不再需要开发特定发行版本的包 更新容器镜像
2. 让ceph支持平滑升级 可以一键升级 并且升级的过程还可以看到 进度条
3. 可以直接使用cephadm来管理ceph集群,无需安装客户端软件
4. 使用cephadm orchestrator 通过web的方式进行管理
cephadm的部署:
1. 指定集群的引导节点(点火节点) cephadm 会在引导节点上创建一个单节点的集群
2. cephadm 通过ssh的方式管理集群中的其他节点
3. cephadm通过编排器 部署相应的服务到集群节点 ——>引导节点会拷贝容器的镜像到集群节点
RHCS5.0 部署
教室环境介绍:
F0中虚拟机的作用:
classroom 教室基础环境 YUM源 软件包
bastion 教室路由器 把网络打通
workstations 测试桌面 教室环境中的各种脚本都要到上面运行
utility 容器的镜像仓库
clientb ceph第二个集群的客户端
serverf serverg ceph的第二个集群
clienta ceph第一个集群的客户端
serverc serverd servere ceph的第一个集群
部署流程:
准备工作: [student@workstation ~]$ lab start deploy-deploy 摧毁已经存在的集群
1. serverc作为引导节点
a) 安装cephadm-ansible 工具 给节点做预配
b) 编写主机清单 vim /usr/share/cephadm-ansible/hosts
clienta.lab.example.com
serverc.lab.example.com
serverd.lab.example.com
servere.lab.example.com
c) 第二步执行 ansible-playbook -i hosts cephadm-preflight.yml --extra-vars "ceph_origin="
d) cephadm bootstrap --mon-ip 172.25.250.12 --apply-spec=initial-config-primary-cluster.yaml --initial-dashboard-password redhat --initial-dashboard-user admin --dashboard-password-noupdate --allow-fqdn-hostname --registry-url registry.lab.example.com --registry-username registry --registry-password redhat 开始部署
e) cephadm shell ——> ceph –s 查看集群的状态
开源pacific版本部署
node1、node2、node3 配置 2H4G 最少的配置
每台机器三块磁盘类型scsi,大小各10G,操作系统rockylinux 8.4
1. 配置主机名和IP的映射关系
a) 172.17.0.81 node1.example.com
b) 172.17.0.82 node2.example.com
c) 172.17.0.83 node3.example.com
2. 节点预配置
a) 关闭selinux和防火墙
b) 配置时间同步且chronyd设置为开机自启 本地的时间源
3. 获取cephadm
到社区找到cephadm的版本
wget https://github.com/ceph/ceph/raw/pacific/src/cephadm/cephadm获取 cephadm
http://rhce.ytlinux.com/cephadm cephadm 16.2.11 版本
4. 配置cephadm
chmod +x cephadm 添加执行权限
./cephadm add-repo --release pacific 添加指定版本的ceph源
./cephadm install 安装cephadm工具
./cephadm install ceph-common 安装ceph的客户端工具(可选)
5. 在引导节点上部署单节点集群
cephadm bootstrap --mon-ip 172.17.0.81 --allow-fqdn-hostname --initial-dashboard-user admin --initial-dashboard-password redhat --dashboard-password-noupdate
bootstrap 引导集群
--mon-ip 172.17.0.81 指定mon节点地址
--allow-fqdn-hostname 使用主机名作为dashboard地址
--initial-dashboard-user admin 指定dashboard用户名为admin
--initial-dashboard-password 指定dashboard密码为redhat
--dashboard-password-noupdate 首次登陆dashboard无需更改密码
6. 各容器的功能作用
ceph-mon mon组件
ceph-mgr mgr组件
ceph-mds mds组件
ceph-osd osd组件
ceph-crash mgr用来收集守护进程的崩溃信息
prometheus 普罗米修斯监控的主程序
node-exporter 普罗米修斯监控程序 Linux收集端,windows使用WMI-exporter
alertmanager 普罗米修斯 报警管理器
7. 给单节点集群添加OSD磁盘
cephadm shell 进入到ceph操作环境
ceph orch daemon add osd node1.example.com:/dev/sdb 添加指定主机的单块磁盘为osd
ceph orch daemon add osd node1.example.com:/dev/sdc
ceph orch daemon add osd node1.example.com:/dev/sdd
ceph orch apply osd --all-available-devices 在所有主机上将未使用的磁盘部署为osd
8. 容器实现的原理
a. cephadm会在被管理主机上释放两个目录
i. 一个是/var/log/ceph 日志目录
ii. 一个是/var/lib/ceph/集群ID ceph集群容器数据的存放目录
b. 每一个服务组件对应一个容器,会在/var/lib/ceph/集群ID/生成一个以服务名命名的目录
c. 每个服务目录中会存在一个名为unit.run的脚本,该脚本对应systemd的一个服务单元,所以每个容器都是通过systemd实现开机自启动的
d. 在osd组件的目录中有一个名为block的文件,该文件则为系统上逻辑卷的软连接文件,对应系统上一个真正的lvm逻辑卷
e. 系统上每一个osd的lvm都是独立的,是单独的PV-VG-LV
9. 各组件服务端口
10. 给集群添加主机
ceph cephadm get-pub-key > ~/ceph.pub 获取集群公钥并保存到当前路径下ceph.pub
ssh-copy-id -f -i ~/ceph.pub root@node2 拷贝公钥到node2
ceph orch host add node2.example.com 需要写完整的主机名
ps: 如果添加主机失败,第一个检查mgr容器是否可以正常解析该主机名,第二个检查ceph的key有没有发送到节点上
11. 管理ceph节点角色
关闭集群组件自扩展
ceph orch apply mon --unmanaged=true 关闭mon自动扩展
ceph orch apply mgr --unmanaged=true 关闭mgr自动扩展
添加mgr节点
ceph orch daemon add mgr --placement=node2.example.com
添加mon节点
ceph orch daemon add mon --placement=node2.example.com
12. 验证集群状态
cephadm shell
ceph -s warn 警告 集群是可用的 只是有错误 一般不影响使用
ok 状态是正常的
error 错误 集群停止运行 无法使用
13. ceph集群的管理
在任何安装了ceph客户端(ceph-common)的主机上,只要存在ceph.conf和ceph.client.admin.keyring 文件且该主机可以访问到ceph的mon节点则可以管理ceph
相关的命令:
ceph orch host ls 查看集群内的主机
ceph orch ls 查看集群内服务的部署情况
ceph orch ps 查看集群内各个主机的服务运行情况
14. 移除集群中的服务和主机
a) 停止服务 ceph orch daemon stop 服务名
b) 删除服务 ceph orch daemon rm 服务名 如果服务正在运行 --force
c) 移除主机 ceph orch host rm node3.example.com 移除前确保主机上的服务停止
15. 移除集群中的osd
a) 停止指定的osd服务 ceph orch daemon stop osd的服务名
b) 删除服务 ceph orch daemon rm osd服务名
c) 删除crushmap的映射 ceph osd rm osd的序号
d) 擦除数据 ceph orch device zap node2.example.com /dev/sdd --force (如果集群开启了osd的自动扩展,则需要关闭,否则会自动将该磁盘重新创建为osd)
16. 使用标签部署服务
a) 标记ceph管理节点以执行cephadm
ceph orch host label add node3.example.com test 给节点添加test 标签
ceph orch host label add node4.example.com test
b) 标记ceph组件节点以批量部署
ceph orch apply mgr --placement="label:test"
PS: apply(应用规则来部署服务) daemon (手动去添加服务) 都可以部署服务
第三章ceph的存储池
存储池概念
存储池是ceph的逻辑分区,专门用来存储对象
特性:
1. 将文件切片成对象 通过hash算法 找到存储池中的pg,池中的pg根据cruash算法找到osd节点
2. 存储池中的PG的数量对性能有重要影响,一般建议OSD上PG的数量100-250(RHCS) 开源一般不要超过200,超过200将导致存储池无法创建,超过限制通过修改存储池的参数来实现mon_max_pg_per_osd
3. 访问级别:不同用户的访问权限
存储池分类
带有数据冗余的池类型
复制池(副本池)
纠删码池
带有数据缓存加速的类型
缓存池
复制池
创建复制池:
ceph osd pool create pool-name
默认创建是副本池、且默认是3副本、pg和pgp默认是32
PG对存储池的影响:
pg数量过多: 数据移动时,每个PG维护的数据量过少,ceph占用大量的cpu和内存计算,影响集群正常客户端使用
pg数量过少:单个pg存储的数据就越多,移动pg会占用大量带宽,影响集群客户端使用
l PG存储池中的个数,PGP是存储池PG的OSD排列组合数
l 扩容pg à pg中的对象会进行移动 在新的osd上生成pg
l 扩容pgp-> pg中的对象不会进行移动 会引起部分pg在osd上的分布
存储池添加应用
存储池添加应用标签(如果不添加应用则ceph会告警):
ceph osd pool application enable pool-name rgw(应用的类型 rgw、rbd、cephfs)
存储池常用命令
• 列出存储池
• ceph osd pool ls 查询池
• ceph osd pool ls detail 查询池的详细信息
• 获取池统计信息
• ceph df:获取池用量统计数据
• ceph osd df:获取osd上磁盘使用量统计数据
• ceph osd pool stats:获取池性能统计数据
rados常用命令
(rados的命令只限在节点上测试使用)
rados -p pool-name ls 查看池中的对象
rados -p pool-name put 对象名 /对象的路径 将对象上传到存储池
rados -p pool-name get 对象名 /对象的路径 将对象从存储池下载到本地
rados -p pool-name rm 对象名 删除对象
存储池配额
配额方式
对象配额 容量配额
语法提示:
ceph osd pool set-quota pool-name max_objects obj-count max_bytes bytes
示例
ceph osd pool set-quota myfirstpool max_objects 1000
可将值设置为0来删除配额。同时通过ceph osd df命令查看池的用量统计数据
当ceph达到池配额时,操作会被无限期阻止
存储池重命名
语法
ceph osd pool rename current-name new-name
示例
ceph osd pool rename mysecondpool mytestpool
重命名池,不影响池中的数据
存储池快照
存储池快照,只能针对池中的单个对象进行还原,不能对整个池进行还原
创建快照
ceph osd pool mksnap pool-name snap-name
查看快照
rados -p pool-name -s snap-name ls
删除快照
ceph osd pool rmsnap pool-name snap-name
回滚快照(还原快照的两种方式)
rados -p pool-name -s snap-name get object-name file 从快照下载对象到本地
rados -p pool-name rollback object-name snap-name 直接从快照还原对象到存储池
存储池参数
设置池参数
ceph osd pool set pool-name parameter value
获取池参数
ceph osd pool get pool-name parameter
列出所有参数及其值
ceph osd pool get pool-name all
PG自动调整
PG的计算方法:
Target PGs per OSD:预估每个OSD的PG数,一般取100计算
集群OSD不增加推荐值为 100 增加为 200
OSD #:集群OSD数量
%Data:预估该存储池占该OSD集群总容量的近似百分比
Size:该存储池的副本数
1. If the result of this calculation is less than (OSD#)/(Size), then the PG Count is updated to (OSD#)/(Size). This tactic ensures an even load/data distribution by allocating at least one Primary or Secondary PG to every OSD for every Pool.
2. The output value of 1 above is then rounded to the nearest value of 2. This rounding marginally improves the efficiency of the CRUSH algorithm.
3. If the nearest power of 2 is more than 25% below the original value (the result of the first equation), we use the next higher power of 2
PG推荐值:
• 一种比较通用的取值规则:
• 少于5个OSD时可把pg_num设置为128
• OSD数量在5到10个时,可把pg_num设置为512
• OSD数量在10到50个时,可把pg_num设置为4096
• OSD数量大于50时,建议自行计算
• PG计算器
• pgcalc:https://ceph.com/pgcalc (ceph官方已废弃)
• cephpgc:https://access.redhat.com/labs/cephpgc
PG autoscaler:
pg_autoscaler存储池选项可以帮助存储池自动调整pg和pgp的数量
PG支持分裂
现有PG可以将其内容“拆分”为许多较小的PG,从而增加了池中PG的总数
PG支持合并
现有两个PG“合并”到一个更大的PG中,从而减少池中PG的总数(N版以后开始支持)
ceph mgr module enable pg_autoscaler N版以后默认开启
集群根据每个池中实际存储(或预期要存储)的数据量,并自动选择适当的pg_num值
存储池命名空间
• namespace是池中对象的逻辑组。可以限制用户对池的访问,使得用户只能存储或检索这个namespace内的对象
• namesapce的优点是能够使将用户访问权限池的某一部分
• namespace目前仅支持使用librados的应用,不支持rgw和rbd
• 若要在命名空间内存储对象,客户端应用必须提供池和命名空间的名称
• 默认情况下,每个池包含一个具有空名称的namespace,称为默认namespace
• rados命令可以通过-N name或者--namespace=name选项存储和检索池中指定命名空间的对象
• 示例
• rados -p mytestpool -N system put srv /etc/services
• rados -p mytestpool -N system ls
• rados -p mytestpool --all ls
• rados -p mytestpool --all ls --format=json | python - json.tool
• --all 可列出池中所有命名空间中的所有对象
• --format=json 返回json格式的结果
删除存储池
• 删除池
• ceph osd pool delete pool-name pool-name --yes-i-really-really-mean-it
• 从L版开始,已将mon_allow_pool_delete配置参数设置为false,以提供额外的保护。即使借助--yes-i-really-really-mean-it选项,ceph osd pool delete命令也不会导致池被删除
• 可以将mon_allow_pool_delete参数设置为true,然后重启mon服务,以允许删除池
• 即使mon_allow_pool_delete被设置为true,也可以通过在池级别上将nodelete选项设置为true来防止池被删除:
• ceph osd pool set pool-name nodelete true
纠删码池
纠删码池的存在就是为了解决ceph存储的容量问题,因为副本机制会导致硬盘上大量的空间用作冗余,使用存储容量相对较少,既要保证数据的冗余性,又要保证数据的可靠性
• 纠删码池使用纠删码而非复制来保护对象数据
• 相对于复制池,纠删码池会节约存储空间,但是需要更多的计算资源
• 纠删码池一般只能用于对象存储(从L版开始可以调整为支持rbd和cephfs)
• 打开池选项allow_ec_overwrites以支持rbd和cephfs
• 纠删码池L版之前不支持快照
纠删码原理
n = k + m
k:数据块 m:编码块(编码块是通过数据块计算得出) n:总的块数
将一个对象切成多个数据块,然后使用m个编码块对数据块进行编码,最后将n个数据块存储到pg,编码块的大小和数据块的大小是一致的,数据块的大小就是将对象均匀的切片,比如一个对象是4M,数据块是2个那么数据块的大小就是2M
任意个K块可以还原数据,m个块一般决定冗余量
l 纠删码的存储方法是将每个object划分成更小的数据块,每一个数据块称为data chunk,再用编码块(coding chunk)对它们进行编码,最后将这些数据块和编码块存储到Ceph集群的不同故障域中,从而保证数据安全。纠删码概念的核心公式n=k+m,解释如下:
p k:原始object被划分成的数据块的个数
p m:附加到所有原始数据块的额外编码块的个数
p n:执行纠删码处理后,所创建的块的总数
编码规则
example: ceph osd erasure-code-profile set ecdemo k=2 m=1 crush-failure-domain=osd
l k:在不同 OSD 之间拆分的数据区块数量。默认值为 2。
l m:数据变得不可⽤之前可以出现故障的 OSD 数量。默认值为 1。
l plugin: 此可选参数定义要使⽤的纠删代码算法。
l crush-failure-domain:CRUSH 故障域,默认设置为 host
l crush-device-class: 典型的类别可能包括 hdd、ssd 或nvme。
l crush-root:此可选参数设置 CRUSH 规则集的根节点。
l key=value: 插件可以具有对该插件唯⼀的键值参数。
l technique:每个插件提供⼀组不同的技术来实施不同的算法。
纠删码profile注意点:无法修改或更新现有纠删码池的profile
纠删码规则操作:
使用指定profile创建纠删码池
ceph osd pool create pool-name erasure profile-name
列出现有的配置
ceph osd erasure-code-profile ls
删除现有的配置
ceph osd erasure-code-profile rm profile-name
查看现有的配置
ceph osd erasure-code-profile get profile-name
第四章ceph集群配置
Ceph配置文件
• 默认情况下,无论是ceph的服务端还是客户端,配置文件都存储在/etc/ceph/ceph.conf文件中
• 如果修改了配置参数,必须使用/etc/ceph/ceph.conf文件在所有节点(包括客户端)上保持一致。
• ceph.conf 采用基于 INI 的文件格式,包含具有 Ceph 守护进程和客户端相关配置的多个部分。每个部分具有一个使用 [name] 标头定义的名称,以及键值对的一个或多个参数
• 配置文件使用#和;来注释
• 参数名称可以使用空格、下划线、中横线来作为分隔符。如osd journal size 、 osd_jounrnal_size 、 osd-journal-size是有效且等同的参数名称
• 通过中括号将特定守护进程的设置分组在一起:
ceph 全局配置文件 /etc/ceph.conf
[global] 部分存储所有守护进程或读取配置的任何进程(包括客户端)所共有的⼀般配置。
[mon] 部分存储监控器 (MON) 的配置。
[osd] 部分存储 OSD 守护进程的配置。
[mgr] 部分存储管理器 (MGR) 的配置。
[mds] 部分存储元数据服务器 (MDS) 的配置。
[client] 部分存储应⽤到所有 Ceph 客户端的配置。
元变量
所谓元变量是即Ceph内置的变量。可以用它来简化ceph.conf文件的配置:
$cluster
红帽 Ceph 存储 5 集群的名称。默认集群名称为 ceph。
$type
守护进程类型,如监控器的值为 mon。OSD 使⽤ osd,元数据服务器使⽤ mds,管理器使⽤mgr,客⼾端软件使⽤ client。
$id
守护进程实例 ID。对于此变量,serverc 上监控器的值为 serverc。osd.1 的 $id 值为 1 ,客⼾端应⽤的值为⽤⼾名。
$name
守护进程名称和实例 ID。此变量是 $type.$id 的简写。
$host
运⾏守护进程的主机的名称。
配置文件路径
$CEPH_CONF(CEPH_CONF环境变量所指示的路径)
-c path / path(ceph -c)
/etc/ceph/ceph.conf
〜/.ceph/ceph.conf
./ceph.conf(就是当前所在的工作路径)
仅限FreeBSD系统, /usr/local/etc/ceph/$cluster.conf
临时修改配置
使用tell修改
ceph tell $type.$id config set mon_allow_pool_delete true 修改某一个服务的配置
ceph tell $type.* config set mon_allow_pool_delete true 修改一整个类型
使用daemon修改(在指定进程的容器中执行)
ceph daemon <name> config set <option> <value>
ceph daemon osd.4 config set debug_osd 20
PS:使用daemon 的方式修改服务的配置,可以在mon故障的情况下进行修改,但是一定要在指定进程的容器中去执行该命令
配置集中式数据库
查看集群中所有的配置项
ceph config ls 列出所有配置项
ceph config help setting 有助于进⾏特定配置设置
ceph config dump 可显示集群配置数据库设置
ceph config show $type.$id 可显⽰特定守护进程的数据库设置
ceph config show-with-defaults $type.$id 查看特定守护进程的默认配置项
查看集群中当前生效的配置项
使⽤ ceph config get $type.$id 可获得特定配置设置
使⽤ ceph config set $type.$id 可设置特定配置设置
ceph config get mon mon_allow_pool_delete (持久生效的)
查看集群中所有的配置项
ceph config ls 列出所有配置项
ceph config help setting 有助于进⾏特定配置设置
ceph config dump 可显示集群配置数据库设置
ceph config show $type.$id 可显⽰特定守护进程的数据库设置
ceph config show-with-defaults $type.$id 查看特定守护进程的默认配置项
查看集群中当前生效的配置项
使⽤ ceph config get $type.$id 可获得特定配置设置
使⽤ ceph config set $type.$id 可设置特定配置设置
管理数据库大小
MON 节点存储和维护集中配置数据库。数据库在每个 MON 节点上的默认位置是 /var/lib/ ceph/$fsid/mon.$host/store.db
ceph tell mon.$id compact 整合指定主机守护进程的数据库
ceph config set mon mon_compact_on_start true mon每次启动时自动压缩
ceph网络架构
l 集群网络类型
p public 公共网络 供客户端和集群节点之间进行通信
p cluster 集群网络 供OSD实现副本创建、数据恢复和再平衡以及心跳通信
l public ⽹络是所有 Ceph 集群通信的默认⽹络
p cephadm ⼯具假定第⼀个 MON 守护进程 IP 地址 的⽹络是 public ⽹络
p Ceph 客⼾端通过集群的 public ⽹络直接向 OSD 发送请求
p 如果没有cluster network OSD 复制和恢复流量会使⽤ public ⽹络
集群网络优势
l 性能:消除副本创建、数据恢复和再平衡对 public network 的压力;增强 OSD 心跳网络的可靠性
l 安全 :集群网络和公共网络隔离通过cluster network,防止例如 DDOS 网络攻击带来的影响
l OSD使用6800-7300范围内三个端口进行通信:
p ⼀个⽤于通过公共⽹络与客⼾端和 MON 通信
p ⼀个⽤于通过集群⽹络或公共⽹络发送数据到其他 OSD
p ⼀个⽤于通过集群⽹络或公共⽹络交换⼼跳数据包
设置集群网络
l 创建集群时配置
p cephadm bootstrap --cluster_network
l 修改已经存在的集群
p cop config set osd cluster_network 172.25.252.0/24
l 启用IPV6
p 默认开启ms_bind_ipv4 true 而 ms_bind_ipv6位false
p ceph config set global ms_bind_ipv6 true
第五章 ceph用户认证及授权
认证说明
认证机制
None:这种模式下,任何用户可以在不经过身份验证时就访问Ceph集群
auth_cluster_required = none
auth_service_required = none
auth_client_required = none
Cephx:Cephx协议类似于Kerberos协议,它允许经过验证的客户端访问ceph集群
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
密钥创建机制
身份验证过程
用户命名规范
Ceph守护进程使用的帐户名与相关守护进程名称匹配:osd.1 或 mon.node1,这些用户默认会在安装时被创建
librados的客户端应用,帐户名以client.开头。例如,将OpenStack与Ceph集成时,常常会创建专用的client.openstack用户。另外,当部署 Ceph Object Gateway时,会创建client.rgw.帐户。如果要在librados基础上部署自定义软件,也应当创建特定帐户
Ceph客户端所使用的帐户名以client.开头,运行ceph和rados等命令时使用。安装程序会创建超级管理员client.admin,它具有访问所有内容及修改集群配置的功能。如果运行命令时不通过 --name 或 --id 明确指定用户名,Ceph默认使用client.admin
Ceph命令的选项
l ceph -s
p --id 用户名
p --name $type.$id client.admin
p --keyring 用户秘钥 /etc/ceph/ceph.client.admin.keyring
p --conf 指定ceph的配置文件
l rados -p pool-name ls
p --id 用户名
p --name $type.$id client.admin
添加用户方式
• ceph auth add
• 当用户不存在,则创建用户并授权
• 当用户存在,当权限不变,则不进行任何输出
• 当用户存在,不支持修改权限
• 示例:ceph auth add client.user1 mon 'allow r' osd 'allow rw pool=pool01’
• ceph auth get-or-create
• 当用户不存在,则创建用户并授权并返回用户和key
• 当用户存在,权限不变,返回用户和key
• 当用户存在,权限修改,则返回报错
• 示例:ceph auth get-or-create client.user1 mon 'allow r' osd 'allow rw pool=pool01'
• ceph auth get-or-create-key
• 当用户不存在,则创建用户并授权只返回key
• 当用户存在,权限不变,只返回key
• 当用户存在,权限修改,则返回报错
• 示例:ceph auth get-or-create client.user1 mon 'allow r' osd 'allow rw pool=pool01'
用户授权的优势
• Ceph把数据以对象的形式存于各存储池中,Ceph用户必须具有访问存储池的权限才能够读写数据
• Ceph用caps来描述给用户的授权,这样才能使用Mon、OSD和MDS的功能
• caps也用于限制对某一存储池内的数据或某个命名空间的访问
• Ceph管理员用户可在创建或更新普通用户时赋予其相应的caps
CAPS权限说明
授权方式
l 普通授权
p mon 'allow r' osd 'allow rw'
l 基于存储池的授权
p mon 'allow r' osd 'allow rw pool=myfirstpool'
l 基于对象前缀授权
p mon 'allow r' osd 'allow rw object_prefix pref'
l 基于命名空间授权
p mon 'allow r' osd 'allow rw pool=myfirstpool namespace=photos'
l 基于路径授权
p 只适用于CephFS,CephFS通过这种方式来限制对特定目录的访问
p mon 'allow r' osd 'allow rw pool=cephfs_data' mds 'allow rw path=/webcontent'
l 限制用户只能使用特定的管理员指令
p mon 'allow r, allow command "auth get-or-create", allow command "auth list"'
caps 授权 权限会发生覆盖,所以如果是新增权限,必须原封不动的带上原来的权限
用户管理
• 查看系统所有用户
• ceph auth list
• 获取某个用户的详细信息
• ceph auth get client.admin
• 获取用户的key
• ceph auth print-key client.admin
• 删除指定用户
• ceph auth del client.bob
用户备份
• 导出用户
• ceph auth get client.bob -o /etc/cephceph.client.bob.keyring
• 导入用户(导入的用户需要有caps权限)
• ceph auth import -i /etc/ceph/ceph.client.bob.keyring
用户秘钥
客户端访问ceph集群时,会使用本地的keyring文件,默认依次查找下列路径和名称的keyring文件:
/etc/ceph/$cluster.$name.keyring
/etc/ceph/$cluster.keyring
/etc/ceph/keyring
/etc/ceph/keyring.bin
PS:无论用户的秘钥放在哪个文件都要确保本机上的ceph用户对该文件有读取的权限
第六章RBD基础使用
RBD介绍
l 块设备是服务器、笔记本电脑和其他计算系统上最为常⻅的⻓期存储设备。它们以固定⼤⼩的块存
储数据。块设备包括基于旋转磁盘的硬盘驱动器,以及基于⾮易失性存储器的固态驱动器。若要使⽤存储,您要使⽤⽂件系统格式化块设备,并将它挂载到 Linux ⽂件系统层次结构中。
l RADOS 块设备 (RBD) 功能可从红 帽 Ceph 存储集群提供块存储。
l RADOS 提供虚拟块设备,并以RBD 镜像形式存储在红帽 Ceph 存储集群的池中。
创建RBD镜像
• 创建RBD池
• ceph osd pool create rbd
• 初始化RBD池
• ceph osd pool application enable rbd rbd
或者
• rbd pool init rbd
• 创建client.rbd用户
• ceph auth get-or-create client.rbd mon 'allow r' osd 'allow rwx pool=rbd‘
• 或者 ceph auth get-or-create client.rbd mon profile rbd' osd ‘profile rbd pool=rbd'
• 创建RBD镜像
• rbd create --size 1G rbd/test
• 在客户端映射镜像
• rbd map rbd/test --name client.rbd
• 格式化并访问
• mkfs.xfs /dev/rbd0
• 挂载镜像
• mount /dev/rbd0 /mnt
RBD查询操作
• 列出所有的rbd
• rbd [--pool pool-name] ls
• 查询指定rbd的详细信息
• rbd info [pool-name/]image-name
• 查询指定rbd的状态信息
• rbd status [pool-name/]image-name
• 查询指定rbd镜像的大小
• rbd du [pool-name/]image-name
RBD扩容与复制
• 修改rbd镜像的大小
• rbd resize [pool-name/]image-name --size nM|G|T
• rbd resize rbd/test --size 2G
• xfs_growfs -d /mnt
• 复制rbd镜像
• rbd cp [pool-name/]src-image-name [pool-name/]tgt-image-name
• 移动rbd镜像(重命名rbd镜像)
• rbd mv [pool-name/]src-image-name [pool-name/]new-image-name
ps:不支持跨池操作,只能在同一个池内进行操作
RBD删除与恢复
• 删除RBD需要先将其移动至回收站
• rbd trash mv [pool-name/]image-name
• 从回收站删除RBD
• rbd trash rm image-id
• 从回收站恢复RBD
• rbd trash restore image-id
• 查看当前回收站中的RBD
• rbd trash ls [pool-name]
RBD映射
l 所有映射操作都需要在客户端执行
• RBD映射
• rbd map [pool-name/]image-name
• 取消映射
• rbd unmap /dev/rbd0
• 查看映射
• rbd showmapped
RBD持久映射
l 编写fstab条目
p /dev/rbd/存储池名/镜像名 /挂载点 文件系统类型 defaults,_netdev 0 0
p /dev/rbd/rbd/images1 /mnt xfs defaults,_netdev 0 0
l 编写rdbmap
p 存储池名/镜像名 id=用户名,keyring=用户keyring文件路径
p rbd/images1 id=rbd,keyring=/etc/ceph/ceph.client.rbd.keyring
l 设置rbdmap服务自启动
p systemctl enable --now rbdmap.service
第七章RBD高级特性
RBD客户端缓存
l RBD客户端两种实现方式
p librbd: RBD块设备在客户端由librbd通过用户空间的库实现,librbd就是利用librados与RBD进行交互的,librbd主要用于为虚拟机提供块设备,librbd无法使用Linux页面缓存
p krbd:使用原生Linux内核模块krbd进行挂载,内核驱动可利用 Linux 页缓存来提升性能
l 缓存模式
p 直写(透写)缓存: 数据直接写入osd磁盘
p 回写缓存: librbd 库将数据写⼊到服务器的本地缓存中,周期性刷盘到OSD(如主机故障有丢失数据的风险)
l RBD缓存
p RBD缓存是使用客户端上的内存
RBD关键特性
RBD镜像特性管理
l 在RHEL7/Centos7中映射rbd可能会报错
p RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable test object-map fast-diff deep-flatten"
p 说明RBD启用了一些内核不支持的功能,需要关闭之后才能正常映射
l 启用RBD镜像特性
p rbd feature enable rbd/test layering
l 禁用RBD镜像特性
p rbd feature disable rbd/test layering
RBD快照
RBD快照是创建于特定时间点的RBD镜像的只读副本
RBD快照使用写时复制(COW)技术来最大程度减少所需的存储空间
在将写⼊ I/O 请求应⽤到 RBD 快照镜像前,集群会将原始数据复制到 I/O 操 作所影响对象的 PG 中的另⼀区域
快照在创建时不会占⽤存储空间,但会随着所包含对象的变化 ⽽增⼤
1. 冻结文件系统
fsfreeze -f mountpoint 冻结文件系统 fsfreeze -u mountpoint 解冻文件系统
2. 创建快照 rbd snap create pool/image@firstsnap
3. 查看快照 rbd snap ls pool/image
4. 回滚快照(先unmap取消映射) rbd snap rollback pool/image@snap
5. 删除快照 rbd snap rm pool/image@snap
快照 COW 步骤在对象级别上运⾏,不受对 RBD 镜像发出的写⼊ I/O 请求⼤⼩的限制。
在有快照的RBD镜像中写⼊⼀个字节,则 Ceph 会将整个受影响的对象从RBD 镜像复制到快照区域
RBD克隆
RBD 克隆是 RBD 镜像的可读写副本,它将受保护的 RBD 快照⽤作基础镜像
父RBD快照和克隆相同的数据会直接从父快照读取 - 对于客户端而言读取效率低下
COR读加速: COR在第一次读取时将对象复制到克隆
克隆管理
l 创建快照
p rbd snap create pool/image@snapshot
l 保护快照
p rbd snap protect pool/image@snapshot
l 使用受保护创建克隆
p rbd clone pool/imagename@snapshotname pool/clonename
l 列出克隆镜像
p rbd children [pool-name/]image-name@snapshot-name
l 将克隆镜像转换为独立镜像
p rbd flatten [pool-name/]child-image-name
RBD导入导出
l 利⽤RBD的导出与导⼊机制,可以在同⼀集群中或另一套集群中拥有完整访问性的 RBD 镜像副本
l RBD导入导出方式: 全量导入导出 增量导入导出
l RBD导入导出应用场景:
p 利⽤实际的数据卷测试新版本
p 利⽤实际的数据卷运⾏质量保障流程
p 实施业务连续性⽅案
p 将备份进程从⽣产块设备分离
全量导入导出
l 主集群全量导出
将正在使用的RBD镜像卸载
rbd unmap pool-name/images
导出RBD镜像到文件
rbd export file-name pool-name/images
从集群全量导入
准备存储池
ceph osd pool create demo
导入镜像到存储池
rbd import file-name pool/images
增量导入导出
l 差异导出
p 导出从创建镜像到第一次快照之间的差异数据
n rbd export-diff pool/images@snap file-name
p 导出镜像到第一次快照和第二次快照之间的差异数据
n rbd export-diff --from-snap pool/images@snap1 pool/images@snap2 file-name
l 差异导入
p rbd import-diff file-name pool/images
第八章RBD镜像Mirror
镜像Mirror
l Ceph采用的是强一致性同步模型,所有副本都必须完成写操作才算一次写入成功,一个请求需要异步返回再确认完成,如果副本在异地,网络延迟就会很大,拖垮整个集群的写性能。因此,Ceph集群很少有跨域部署的,也就缺乏异地容灾
镜像Mirror优缺点
l 优点:
p 当副本在异地的情况下,减少了单个集群不同节点间的数据写入延迟
p 减少本地集群或异地集群由于意外断电导致的数据丢失
l 缺点:
p 成本高昂
p 如果人为误操作删除镜像,则异地镜像也会被删除
RBD mirror流程
1.当接收到一个写入请求后,I/O会先写入主集群的Image Journal
2. Journal写入成功后,通知客户端
3.客户端得到响应后,开始写入image
4.备份集群的mirror进程发现主集群的Journal有更新后,从主集群的Journal读取数据,写入备份集群
5.备份集群写入成功后,会更新主集群Journal中的元数据,表示该I/O的Journal已经同步完成
6.主集群会定期检查,删除已经写入备份集群的Journal数据
7. Jewel版本中30s为一次工作周期
RBD Mirror特性
• Mirror模式:
• pool-mode(存储池模式)
• 一个存储池内的所有镜像都会进行备份
• images-mode(镜像模式)
• 只有指定镜像才会备份
• Mirror同步方式:
• 单向同步
• 主-从同步 支持一对多
• 双向同步
• 主-主同步 仅能一对一
单向同步
• 当数据从主集群备份到备用集群的时候,rbd-mirror仅在备份集群运行
• 可以配置多个从集群
单向同步配置-池模式
l 主集群操作步骤:
p 创建rbd存储池
n ceph osd pool create pool01
p 创建镜像并开启日志和排它锁特性
n rbd create pool01/image1 --image-feature exclusive-lock,journaling --size 1024
p 开启池Mirror模式
n rbd mirror pool enable rbd pool
p 对同伴集群做互信并导出互信秘钥
n rbd mirror pool peer bootstrap create --site-name prod pool01 > /root/prod
– site-name 指定集群的站点名称 为 prod
– pool01 存储池名称
l 从集群操作步骤:
p 创建rbd存储池
n ceph osd pool create pool01(池的名字)
p 安装rbd mirror
n ceph orch apply rbd-mirror placement=serverf.lab.example.com
p 导入同伴集群授信key
n rbd mirror pool peer bootstrap import --site-name backup --direction rx-only pool01 /root/prod
p 查看同步信息
n rbd mirror pool info pool01 查看存储池的同步信息
n rbd mirror pool status pool01 查看存储池的同步状态(从集群上操作)
n rbd mirror pool peer remove 存储池名 UUID 删除互信关系停止Mirror
双向同步
• 如果两个集群互为备份的时候,rbd-mirror需要在两个集群上都运行
• 只能在两个集群之间运行
• 主集群操作步骤:
• 创建rbd存储池
• ceph osd pool create pool01
• 创建镜像并开启日志和排它锁特性
• rbd create pool01/image1 --image-feature exclusive-lock,journaling --size 1024
• 开启池Mirror模式
• rbd mirror pool enable rbd pool
• 安装rbd mirror rbd-mirror placement=serverc.lab.example.com
• ceph orch apply
• 对同伴集群做互信并导出互信秘钥
• rbd mirror pool peer bootstrap create --site-name prod pool01 > /root/prod
• 从集群操作步骤:
• 创建rbd存储池
• ceph osd pool create pool01(池的名字)
• 安装rbd mirror
• ceph orch apply rbd-mirror placement=serverf.lab.example.com
• 导入同伴集群授信key
• rbd mirror pool peer bootstrap import --site-name backup --direction rx-tx pool01 /root/prod
RBD镜像故障转移
• 正常关机故障转移
• 1. 关掉所有正在使用的主image客户端
• 2. 将主集群的主image降级
• 3. 将backup集群的主image升级
• 4. 重新让客户端连接新的主image
• 非正常关机故障转移
• 1. 确认主集群异常无法进行正常操作
• 2. 停止所有使用主image的客户端
• 3. 将backup集群的非主状态的image升级为主image,需要使用--force选项
• 4. 重新让客户端连接新的主image
• 镜像主备提升
– rbd mirror image demote test1 # 先将主镜像降级
– rbd mirror image promote test1 # 再将备镜像提升为主
第九章ceph对象存储
对象存储介绍
l 对象存储将数据存储为离散项,每⼀项即为⼀个对象。与⽂件系统中的⽂件不同,对象不会整理到 由⽬录和⼦⽬录组成的树中,⽽是存储在扁平的命名空间中。每个对象通过使⽤对象的唯⼀对象 ID(也称对象密钥)来检索
l 对象存储不会使用普通的文件系统来访问对象数据,而是通过RESET API来发送和接收对象
l Ceph支持使用Amazon S3(简单存储服务)和 OpenStack Swift 的API来进行访问
l 对象存储中的对象不整理到目录树中,而是存储在扁平的命名空间中,Amazon S3将这个扁平命名空间称为bucket。而swift则将其称为容器,ceph中常用存储桶来进行命名
l 无论是存储桶,还是容器都无法进行嵌套
l bucket需要被授权才能访问到,一个帐户可以对多个bucket授权,而权限可以不同
l 对象存储的优点:易扩展、快速检索
RGW网关介绍
1. RADOS网关也称为Ceph对象网关、RADOSGW、RGW,是一种服务,使客户端能够利用标准对象存储API来访问Ceph集群。它支持S3和Swift API
2. rgw运行于librados之上,事实上就是一个称之为Beast的web服务器来响应api请求
3. 客户端使用标准api与rgw通信,而rgw则使用librados与ceph集群通信
rgw客户端通过s3或者swift api使用rgw用户进行身份验证。然后rgw网关代表用户利用cephx与ceph存储进行身份验证
RGW名词概念
l realm
p 一个realm代表了全局唯一的命名空间,这个命名空间由一个或者多个zonegroup,zonegroup可以包含一个或多个zone,zone包含了桶,桶里包含依次存放的对象
p 每个realm都有与之对应period,每个period及时地代表了zonegroup的状态和zone的配置。每次需要对zonegroup或者zone做修改的时,需要更新period,并提交
l zone group
p ceph支持多zonegroup,每个zonegroup由一个或多个zone组成。在相同的realm中,在同一个zonegroup中的对象共享一个全局命名空间,在跨zonegroup和zone中具有唯一的对象ID
l zone
p realm配置是由一个zonegroup和多zone组成,每个zone是由一个或者多个rgw组成。每个zone由自身的ceph集群支撑。在一个zonegroup中,多zone可以提供容灾能力
部署RGW网关
l 创建realm,设置成默认的realm
p radosgw-admin realm create --rgw-realm=myrealm --default
l 创建zonegroup,指定realm
p radosgw-admin zonegroup create --rgw-realm=myrealm --rgw-zonegroup=myzonegroup --master --default
l 创建zone,指定zonegroup和realm
p radosgw-admin zone create --rgw-realm=myrealm --rgw-zonegroup=myzonegroup --rgw-zone=myzone --master --default
l 提交修改
p radosgw-admin period update --rgw-realm=myrealm --commit
l 创建rgw
p ceph orch apply rgw test --realm=myrealm --zone=myzone --placement="2 serverc.lab.example.com serverd.lab.example.com" --port=8080
l 查看rgw服务和进程
p ceph orch ps 查看进程daemon
p ceph orch ls 查看service
p ceph orch rm rgw.test
l 修改rgw个数和配置
p ceph orch apply rgw test --realm=myrealm --zone=myzone --placement="4 serverc.lab.example.com serverd.lab.example.com" --port=8080
存储池作用
l .rgw.root - 存储信息记录
l default.rgw.control - 用作控制池
l default.rgw.meta - 存储 user_keys 和其他关键元数据
l default.rgw.log - 包含所有存储桶/容器和对象操作(如创建、读取和删除)的⽇志
l default.rgw.buckets.index - 存储存储桶的索引
l default.rgw.buckets.data - 存储存储桶数据
l default.rgw.buckets.non-ec - ⽤于多部分对象元数据上传
用户管理
l 创建用户
p radosgw-admin user create --uid=user1 --access-key=123 --secret=456 --email=user1@example.com --display-name=user1 创建s3用户
l 查询用户
p radosgw-admin user info --uid=user1
l 修改用户
p radosgw-admin user modify --uid=user1 --display-name='user1 li' --max-buckets=500
l 禁用或启用用户
p radosgw-admin user suspend/enable --uid=user1
l 创建key
p radosgw-admin user create/modify --uid=user1 --access-key=abc --secret=def
l 删除key
p radosgw-admin key rm --uid=user1 --access-key=abc
l 自动生成key
p radosgw-admin key create --uid=user1 --gen-access-key --gen-secret
设置配额
l 开启配额
p radosgw-admin quota enable --quota-scope=user --uid=user1 用户配额
p radosgw-admin quota enable --quota-scope=bucket --uid=user1 bucket 配额
l 设置配额
p radosgw-admin quota set --quota-scope=user --uid=user1 --max-objects=1024 --max-size=1G
p radosgw-admin quota set --quota-scope=bucket --uid=user1 --max-objects=1024 --max-size=1G
使用s3访问rgw
l 安装s3客户端
p windows: S3 Browser
p Linux:早期s3cmd à awscli yum install awscli -y
n YUM源地址:http://content.example.com/rhel8.4/x86_64/rhel8-additional/epel-8-for-x86_64-rpms
l 配置用户凭据
p aws configure --profile=ceph 输入用户的ak和sk
l 创建桶
p aws --profile=ceph --endpoint-url=http://serverc:8080 s3 mb s3://bucket1
l 上传对象
p aws --profile=ceph --endpoint-url=http://serverc:8080 --acl=public-read-write s3 cp /etc/passwd s3://bucket1/
l 测试下载
p wget http://serverc:8080/bucket1/passwd
